
Security code reviews is a task that I do on a daily basis, and have been doing for the last thirteen and a half years. In this time, I have reviewed several hundred code bases, and have come across cryptographic code many times. More often than not, there have been security issues in cryptography code that I have reviewed. Very often I have traced these bogus code snippets to StackOverflow answers that got highly upvoted. In this blog, I point out those bad snippets and tell why they are wrong. I also give advice on how to do it right.
I’m not doing this to shame those who have made mistakes: Instead, I want to do my part to help fix the problem. As an AppSec specialist, I get really tired of having the same discussions over and over. I try real hard to make it easy for people to do the right thing: I point them to code that is safe to use, such as Luke Park’s Secure Compatible Encryption Examples. Despite this, there are the occasional teams who just continue to resist, even before the code has made it to production which is the best time to fix it. This makes everybody’s lives more difficult: it wastes my time to have to explain to them why their code is wrong, and it forces the teams to have to do a lot more work later because once the bad cryptography is in production, they need a migration plan to fix it.
I do believe the future has hope for having less cryptography security problems. Many cryptography implementations are having improved APIs, which was largely driven by Dan Bernstein’s NaCl. Also, StackOverflow is no longer pinning the accepted answer as the top answer. This gives people opportunity to upvote better answers than what was originally accepted. You can take that as a cue. Let’s be nice: upvoting the good is better than downvoting the bad.
Now let’s get to the nitty-gritty.
Example 1: AES-128 CBC Mode in Java
The link is here. At the time of writing, this answer has 248 upvotes: It is both the most popular answer and the selected answer. To begin to understand why it is wrong, look at the types of the key and the initVector: they are strings. They should be byte arrays.

The string for the key is a common problem I see. If you are using a string, then you have a password. Passwords are not cryptographic keys, but they can be converted to cryptographic keys with a password based key derivation function. What should not be done is exactly what was done here: copying the password string (which was incorrectly labelled called a ‘key’) into a SecretKeySpec structure.
The string for the IV is a less common mistake, but it is still wrong. Before I explain the fix, let’s look at the calling function:

The problems are:
- Hard-coded password (mislabeled as a key).
- Hard-coded IV that is type String.
I know some people are going to argue that this is just a proof-of-concept and any sane individual would know how to do the right thing for the password and IV. My response is that these people obviously do not review code for a living because I have seen code like this in reputable places that you would never expect to make mistakes like this. It’s a real problem and it is very common.
To illustrate the difference between a key and a password: a 128-bit key should have 128-bits of entropy, so breaking it requires 2128 effort. The solution here has chosen a password from the set of upper case letter, lower case letters, and digits. If they had chosen a completely random password from this set, then that’s 6616 possibilities, which is on the order of 296. That means a cracking effort of at most 296, but actually it gets worse because people do not choose passwords randomly. Way too often I see passwords used for encryption that are very predictable followed by something like ‘123!’. It is sad that people have been conditioned to believe that following deprecated password security guidance (“password composition rules“) somehow makes things secure. It doesn’t: don’t do it.
This is important: do not use the same IV twice — it breaks the security properties. This is explained in my blog Top 10 Developer Crypto Mistakes. I get into way too many arguments about this. Especially when someone responds with “It’s okay — we will put the IV in the vault,” my frustration level sky-rockets. No, it’s not okay: IVs are not intended to be secret, and even if they are hidden, it does not fix the security problem. Quit rolling your own crypto! Unfortunately so many do not understand that they are rolling their own crypto.
There’s one more problem with this code: it is using unauthenticated encryption. In my Top 10 Developer Crypto Mistakes blog, I listed #7 as “Assuming encryption provides message integrity.” I now accept the philosophical advice that used in the design of NaCl: developers should not need to know the difference, instead authenticated encryption should always be used, which covers both bases. In this case, AES in GCM mode solves this problem, CBC mode does not.
A much better answer in the same thread is here by user Patrick Favre. Please review it yourself and if you accept it as a good answer like I did, then upvote it.
Example 2: AES-256 in CBC mode in C#
The code is here.
At the time of writing, this is the second most popular answer with 117 upvotes. It was not the selected answer, but it is still very popular.
The first problem in the code is obvious, the others may not be. See screenshot:

So yes, another case of hard-coded password, which is mislabeled as a key. But the good news is that they used a password based key derivation function (Rfc2898DeriveBytes, which is PBKDF2 using HMAC_SHA1) to turn it into a real key! That’s kind of good, but since they are not specifying an iteration count (you need to scroll to the right on the StackOverflow page to see this), the default value of 1000 is used which is very low (i.e. not very secure) by modern standards.
Now let’s scroll to the right, we see what they fed into Rfc2898DeriveBytes for the salt:

A hard-coded salt! Salts do not need to be secret, but in many cases you should not use the same salt twice. Regardless, it’s best not to have that salt hard-coded.
True story: I saw this exact snippet in a code review for a client. I remember looking at the salt and thinking “that looks very ASCII to me.” So I wrote a program in C to print it out as a string and the result was: “Ivan Medvedev.” I then Googled the IV and came to this snippet on Stack Overflow! I just wondered who this poor Ivan Medvedev is who has his name permanently engraved in insecure code!
So let’s get to the last problem: What’s wrong with the IV? Answer: if the salt and key are constant inputs, then you always get the same IV output. Hence you are using the same IV more than once, which breaks the security of any block cipher in CBC mode.
If the author would have simply copied the Microsoft Rfc2898DeriveBytes example, they would have been much closer to a good answer. But there is still the unauthenticated encryption problem which comes with CBC mode, and Microsoft’s example also has too few iterations.
The somewhat good news is that the selected answer on StackOverflow is better and has much more upvotes. However it too still has problems: the iteration count for Rfc2898DeriveBytes( ) is too small and they are using unauthenticated encryption (CBC mode).
What is a good iteration count is not set in stone. NIST says “the iteration count SHOULD be as large as verification server performance will allow, typically at least 10,000 iterations.” OWASP says at least 720,000 iterations. That’s quite a gap between the two: you might want to read what Thomas Pornin says. Regardless, anything less than 10,000 is definitely too low by modern standards.
Example 3: Triple DES in Java
The code is here.
This question was asked in 2008, so you might excuse some of the problems. At this time, NIST was recommending AES but still allowing Triple DES in some cases. Nowadays triple DES is completely deprecated because the block size is too small, but I still see it in code sometimes.
Let’s look closer at the top answer that has 68 upvotes at the time of writing:

Again, a hard-coded password, but this one is transformed into a key using MD5 which has been deprecated since 1996. However, an additional problem is that MD5 is not a password based key derivation function, so it has no business as being used as one like we see here. PBKDF2 had been a standard since 2000 and should have been used.
This code uses a zero IV, which is a very common problem that I have seen in many code bases. It is also unauthenticated, but that may be excusable because the concept of unauthenticated encryption was not well known at this time.
Please never use any code like this.
Example 4: AES in Java
The code is here. This one has 15 upvotes at the time of writing.
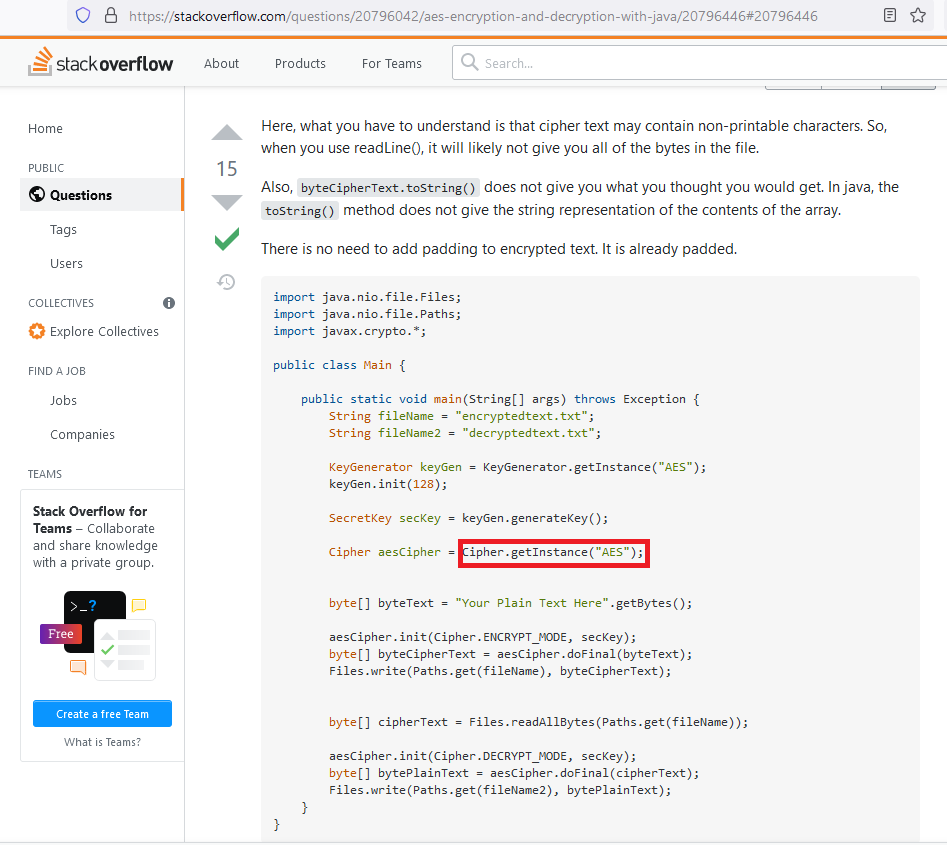
You may notice that he does not specify an IV. That’s probably because he hasn’t specified a mode of operation, and for most cryptographic providers, that means getting a default ECB mode of operation. You should never use ECB: Remember the encrypted penguin picture?
A better answer in this thread has only 11 upvotes. It has CBC mode and and IV chosen properly. It’s not authenticated encryption, but otherwise it is quite a reasonable answer.
Example 5: Please don’t ever do this!
The answer is here. I’m not going to give a screenshot: this one is just too awful.
The question was how to encrypt a string in Java. The selected answer, which has 23 upvotes at the time of writing, is an attempt at implementing a one-time-pad. There has been a warning posted on the top of the answer suggesting that this should never be used. That is 100% correct: a problem with one-time-pads is that they tend to be n-time-pads in practice, where n > 1. Using the pad more than once makes it very easy to crack the encryption.
This is a good example where the change by StackOverflow to make the highest voted issue show up first is paying off. The current highest voted issue has 187 upvotes at the time of writing. This answer gives a nice overall education about how to do encryption properly, and it is definitely worth a read. The only niggle I have is the SecureRandom( ) confusion, which the author knows acknowledges is not right. The risk here is really very small, but the right way to use SecureRandom( ) is very simple.
Am I cherry picking?
You may say that I am pointing out old code, but honestly these code snippets are good representations of the problems I see very often in my daily duties. I rarely see crypto done right.
You can help in improving the state of crypto by upvoting the better answers. This is preferable to downvoting the bad examples highlighted above: let’s solve this problem in the friendly way rather than the mean way. StackOverflow has made the change to allow us to do that.
Why are there so many bad cryptography implementations out there?
The reasons why there are so many bad cryptography examples comes down to history. Historically, there has been a large disconnect between the cryptographic community and the development community. When freely available cryptographic libraries started becoming available from the 1990s, the APIs assumed that developers would know how to use them safely. This was of course a wrong assumption, and combined with the complexity of use, developers spent a lot of effort just trying to make things work. Once they had working code, they were generous to share it with others — not realising that they were tip-toeing through a minefield.
The future looks better for cryptographic implementations, but the first step to getting there is to raise awareness of the good answers and to be very clear about which answers are not valid. This blog is one in several ways that I am trying to be just one small voice helping in make that change.
Addendum
I would like to acknowledge reddit user cym13 for his valuable feedback on this blog, which helped improved the end result.
I would also like to thank the author of cryptohack.org for pointing out a mistake in an earlier version of this blog: for Example 3, I had said authenticated encryption had not been around back then. I was wrong. So I updated the blog to say it was not well known back then.
I would also like to thank Ivan Medvedev for replying to this blog.
There are a number of crypto vigilantes on StackOverflow that frequently leave comments about security problems and how to fix them, such as Maarten Bodewes and ArtjomB. They are experts on the subject.
One desired result was achieved within the first day of posting this blog: in Example 4 above, the better answer has been upvoted enough to surpass the bad answer. Thanks heaps to the community readers who helped make that happen. There has also been a large number of upvotes in the better answer for Example 1, but it still has a long way to go to pass the other answer. Regardless, we have made progress!
