
This blog connects two of my favourite pastimes. It shows that solving the world’s most popular puzzle, the Rubik’s cube, has a perhaps surprsing relationship to the science of cracking secret codes, cryptology. To make it concrete, my cryptology focus will be on how the Polish cryptographers broke the Enigma cipher in World War II. I will show parallels between how hard it is to “brute force” all possible combinations in both cases, versus the clever techniques that give us shortcuts to finding the solutions fast.
Both topics can involve advanced mathematics in combinatorics and group theory, but I will keep it somewhat light so to be accessible to a large audience. I hope this comes off as a fun read, with a sprinkling of mathematics and history.
Remark: cryptology and cryptography are sometimes considered interchangeable, but cryptology explicitly includes cracking ciphers.
The Rubik’s Cube
I’m going to assume that everybody knows what the Rubik’s cube is. The number of possible combinations is 43,252,003,274,489,856,000 (approx 43 quintillion). Nobody has ever tried them all: if they tried, they would die long before they finished. But it helps to understand where this number comes from.
The cube has 6 middle pieces each with one face, 8 corners each with three faces, and 12 edges each with two faces. You can physically pull out the corners and edges and you are left with only the 6 middle pieces that are fixed:

Now imagine we wanted to achieve the ultimate mixup by putting the pieces back together in a random order. This would give us a truly random mixup, and we can use this idea to calculate the number of total possible mixups and hence the total number of combinations that was mentioned above… almost! There is a small problem with this logic, but we’ll get to that soon. But let’s look at trying this approach.
First consider putting in the edges back in place. Take an edge, such as the blue/red edge, and put it in some place on the cube. How many places can it go? There’s 12 spots for edges, and it can go in any one of those spots. But also, we can insert it two ways: either with the blue face facing upward (or forward/downward/backward depending on where you are putting it) or the red face facing this way. So that’s 12×2 possibilities for the first edge.

What about the next edge? There’s only 11 spots left and it can go in any one. Likewise, there are 2 ways to put it in so that’s 11×2. For the third edge, there are 10 spots and 2 ways to put it. You get the idea. In total there are
(12×2)×(11×2)x(10×2)×(9x2)×(8×2)×(7×2)×(6×2)×(5×2)×(4×2)×(3×2)×(2×2)×(1×2) combinations. This can be written simpler by grouping terms and using the factorial operator: 12! x 212.
Now we can do the same thing with corner pieces. We grab the first corner and notice eight possible positions to put it in. Depending upon which face is up (or forward/down/backward), there are three different ways to insert it. That means 8 x 3 possible ways for the first corner. Likewise, there are 7×3 ways for the second corner. You can do the rest, the total possible combinations for the corners are:
(8x3)x(7x3)x(6x3)x(5x3)x(4x3)x(3x3)x(2x3)x(1x3)The short way to write this is 8! × 38.

So the total number ways of putting it back together is the product of these values: 12! × 212 × 8! × 38. Almost there, but as I said before this is not the real total number of mixups! The reason why is because when we turn the cube the ways that it allows us to turn it, it cannot reach all of these mixups. It turns out that out of all those combinations, the last corner that you insert cannot go all three possible ways: only one of them agrees with a valid mixup. Because of this, we need to divide the above value by 3. Similarly, there is a dependency on the edges that requires us to divide by 4. In other words, we have to divide the quantity above by 3 × 4 = 12, and hence the total number of combinations is:
12! × 212 × 8! × 38 / 12 = 43,252,003,274,489,856,000With that background, we can now talk about how we can solve it faster without going through all these combinations!
Solving the Cube Faster With Shortcuts
Before we discuss the mathematics, let’s throw out a few fun facts. The first is that any mixup can be solved in at most 20 moves (where a half-turn is counted as a single move). This is known as God’s Number, and it was proved by Tom Rokicki et al and computing power donated by Google (see also https://www.cube20.org/ and the scientific publication). Nowadays there are online solvers such as https://rubiks-cube-solver.com/ that can show you a solution involving at most 20 moves for the mixup that you have.
Unfortunately, these online solvers work for computers, and are too complex for humans to memorise. Instead, the speed solvers of today use methods like CFOP or Roux, and average in the mid 40s to low 50s number of moves. The current official WCA (World Cubing Association) world record for average of 5 solves is 5.09 seconds by Tymon Kolasiński from Poland, however there are a handful of cubers that could beat the record on a really good day so we could be seeing sub-5 second averages in the near future. Tymon uses the CFOP method.
For our purposes, we just want to explain concepts and connect it to breaking the Enigma cipher in World War II. The easiest way to do that, is to look at a simpler solution method known as corners first.
Corners first is a very old way of solving the cube: few people do it today, and most of us who do are old farts. The first WCA world record of 22.95 seconds was set using the corners first method nearly 40 years ago by my hero Minh Thai. 22.95 seconds is quite slow by modern standards, but it’s a bit of an unfair comparison because Minh had to use the original Rubik’s brand of cube, which is very hard to move. Modern cubers are free to use any brand they want, and these cubes are much more efficient than what Minh Thai used. Having said that, I don’t think anyone would disagree that modern cubers have better methods than the classic corners first and are superior solvers.
The idea of corners first is, as the name suggests, to first get the corners in place, and then solve the edges. The main point is that corners are edges can be solved independently: once the corners are in place, one can move edges around without affecting the corners — they still remain in place. The mathematical consequence is that by knowing that we can work on the two parts independently, the maximum number of tries we need is not the number of possibilities for corners multiplied by the number of possibilities for edges, but instead it is the sum of the two: 8! × 38/3 + 12! × 212 / 4. In other words, if we do one first and then the other, it becomes a sum, but if we are doing both at the same time without taking advantage of being able to work on them independently, the work factor is multiplied.
This already is a huge speed improvement, but it’s still an awfully big number. We learn other tricks to make the number of moves smaller. Getting corners in place can take at most 11 moves, but for me it probably takes around 20. I then get edges for the top and bottom layer fairly easily, and last I solve the middle layer independently of the top and bottom layers. The more work you make independent of other work, the faster it becomes. This is the key takeaway from this section, and we will show the same concept was used to break the Enigma cipher.
For those who want to learn more about speed cubing today, I highly recommend the Speedcubers documentary on Netflix. I promise, my hero Feliks Zemdegs is every bit as cool as he seems in this documentary.
The Enigma Cipher
While the Americans, British, and likely other countries have their own success stories about how breaking codes made a big difference to the outcome of the wars, I am particularly drawn to the way Marian Rejewski and the Polish cryptographers used the theory of permutations (group theory) to find mathematical weaknesses in the German Enigma cipher. This knowledge was shared with the Britain and France shortly before Germany invaded Poland in 1939. The information exchange from the Polish cryptographers was the main building block that Alan Turing and British cryptographers needed to develop more advances on breaking the Enigma Cipher.

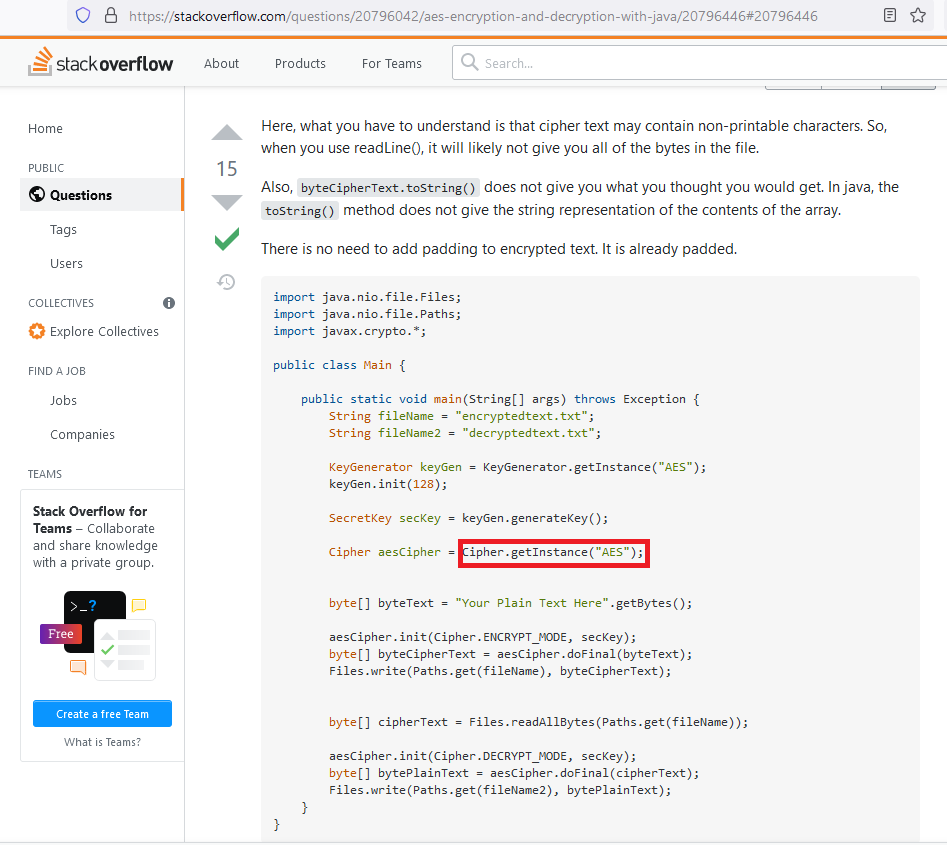
First we need to understand the Enigma cipher before we draw parallels with the Rubik’s cube. Below is the Wikipedia photo of an Enigma machine. I will give a simplified explanation to keep the blog from being too long.

The following 3 minute YouTube video is shows how the cipher works:
In the back, there are some rotors with numbers on them. Think of them as mapping letters to other letters via electric circuits. The rotors work together: if one maps the letter A to F; the next maps F to X; and the third maps X to K, then that means when put together A will map to K. However when a letter is encrypted, the rotors rotate, which changes the mapping. Example: instead of A being mapped to F, B will take that spot and A gets mapped to another letter. The right-most rotor will rotate every time a letter is encrypted, the middle rotor will rotate after the left most has rotated a full 26 times, and the left-most rotor will rotate after the middle has rotated a full 26 times. This means that the three rotors combined can provide 26×26×26 = 17,576 combinations to encrypt messages.
That by itself is not a big enough number to prevent brute force decryption, so Enigma includes the plugboard that is seen at the front. This involves 10 plugs each of which swap two letters around (remark: Rejewski talks of 6 plugs being used, but other accounts said 10 were being used: perhaps Germany upped the number of plugs later in the war). I’ll skip the mathematical explanation, but that results in a total of 26! / (6! 10! 210) = 150,738,274,937,250 combinations.
This means that the total number of possible combinations for the plugboard and the three rotors was:
263 × 26! / (6! 10! 210) = 2,649,375,920,297,106,000This is over 2 quintillion combinations, whereas Rubik’s cube had over 43 quintillion combinations! It helps visually to compare these values side-by-side:
2,649,375,920,297,106,000 : Enigma Combinations
versus
43,252,003,274,489,856,000 : Rubik's Cube Combinations
These numbers are on similar orders of magnitude already, but there were additional factors involved with Enigma that made the number of combinations even higher. For example, there were at least 5 different rotors that could be used and 3 were selected from them and put in any different order (the figure above does not even consider order of the rotors). This by itself results in a multiplier of at least 60, bringing the total number of combinations to almost 159 quintillion. Okay, I’ll write it out:
158,962,555,217,826,360,000 : Enigma Combinations (5 rotors to
choose 3 from)
versus
43,252,003,274,489,856,000 : Rubik's Cube Combinations
Remark: other sources may give different figures: it depends upon number of plugs used and number of rotors used and these factors were not constant throughout the war.
Now remember, in the Rubik’s cube case, we saw that being able to work on corners independently of edges immediately squashed the total number of combinations down: it switches the multiply into a sum. With that background, guess what the Polish cryptographers discovered…. Time’s up. They discovered a trick that allowed them to solve the rotor positions independently of solving the plugboard! As a consequence, the multiply becomes a sum in terms of number of combinations they actually had to try to solve it. Similar to the Rubik’s cube, they found other shortcuts for figuring out the plugboard once they knew the rotor positions that ended up making that part real easy.
How the Polish cryptographers did this involves a lesson in group theory: we will not go that deep. But as an overview, they needed about 80 messages encrypted with the same daily encryption key to derive a “fingerprint” of the rotor positions. Rejewski called this fingerprint the “characteristic.” By constructing a huge catalogue of all possible characteristics for all the rotor positions, they could quickly look up a small set of possible rotor positions for the daily key. It required a little extra effort to find the exact one. Building the huge catalogue was done with machine that they built called the cyclometer. More info can be found in this pdf or Simon Singh’s The Code Book.
Cracking of the Enigma cipher played a very important role for the Allies in World War II. Prior to these discoveries, the Enigma cipher was thought to be unbreakable due to the large number of combinations to find the right key. In fact, it was mathematically flawed as the Polish illustrated. Some people believe cracking Enigma was largely due to operator error. While it was true that there were a number of operator errors during the war, Enigma is not secure by modern standards because it is vulnerable to known plaintext attacks.
Summary
We could think of solving the Rubik’s cube as similar to breaking cryptographic codes: both involve finding shortcuts among the large number of possible solutions in order to find the answer quickly. Although my specific focus here was on similarities between solving the cube and how the Enigma cipher was broken, this same style of thinking is often used to break other ciphers. For the mathematical/programmer reader, I give other examples in my blog So, You Want to Learn to Break Ciphers.
There are people who believe that solving the Rubik’s cube as a useless skill. I strongly disagree with that: it teaches rigour, creativity, and complex problem solving. My focus in this blog was on these value in my own specialty, cryptography, but the skill of breaking down a complex problem into small manageable steps will benefit people in many different ways throughout their lives.









{kind=link}
_-_Museo_scienza_e_tecnologia_Milano.jpg){kind=link}