
Whenever one reads about a security breach like what happened to Capital One, security experts are eager to find out the anatomy of the attack. Little by little, details have emerged. Initially called a firewall misconfiguration problem, later reports seemed to suggest a Server Side Request Forgery attack (SSRF) vulnerability. These conflicting stories do not seem to be publicly resolved. In fact, even a recent story from Wired is still suggesting firewall misconfiguration. One thing that is clear is that Amazon is sticking to the firewall misconfiguration story while trying to remove themselves from any blame:
“It’s inaccurate to argue that the Capital One breach was caused by IAM in any way. The intrusion was caused by a misconfiguration of a web application firewall and not the underlying cloud-based infrastructure“
Which is it, firewall misconfiguration or SSRF, and if Amazon is not to blame, then who is?
Firewall Misconfiguration or SSRF?
It is not so common to hear of a web application being taken over due to a misconfigured firewall, so this sounded curious from the beginning. The closest I have been able to find to make any sense of this comes from Krebs:
“According to a source with direct knowledge of the breach investigation, the problem stemmed in part from a misconfigured open-source Web Application Firewall (WAF) that Capital One was using as part of its operations hosted in the cloud with Amazon Web Services (AWS).
“Known as “ModSecurity,” this WAF is deployed along with the open-source Apache Web server to provide protections against several classes of vulnerabilities that attackers most commonly use to compromise the security of Web-based applications.
“The misconfiguration of the WAF allowed the intruder to trick the firewall into relaying requests to a key back-end resource on the AWS platform.”
Krebs then goes on to explain how the attacker performed SSRF on the web application to access the Amazon instance metadata, which allowed her to access IAM Role credentials and own the EC2 instance.
From this, we are actually starting to get some insight. Indeed, the root cause of the problem does not seem to be a misconfigured firewall — instead it was an application SSRF vulnerability, which is a common theme for AWS hacks — in fact many tutorials about SSRF talk exactly about abusing AWS EC2 instances.
For those not familiar with SSRF, I strongly recommend this Contra Application Security tutorial that shows how Capital One might have been breached. Assuming the accuracy, I must emphasize that it did not take a hacking genius to find this vulnerability. This attack is low hanging fruit.
For Amazon and others to suggest that the problem was a misconfigured firewall shows a fundamental misunderstanding of web security. Quite frankly, I find it shocking that one of the top cloud providers is is going with this line of argument, so time to speak out:
WAFs are not a magic solution to your security problems
What is evident from the above quotes is that a WAF configuration is being blamed for web application vulnerability. This is entirely the wrong security mindset.
When a web application is built, security has to be part of the design. It is not something that is added on at the end: “Now turn on your WAF, then you’re secure!” Nonsense! Sure, WAF vendors are there to sell a product, so they like to claim things that are stretching the truth. But a company like Amazon should know better, and for them to point the finger at the WAF is very telling into the security immaturity of Amazon.
WAFs simply do not solve all security problems. WAFs are a backup protection — if security protections were built into the application itself, then the WAF would offer no value. In reality, developers make mistakes, so the WAF is a fallback security mechanism that can help when other things fail. It is however by no means the primary form of defence.
WAF vendors need to be kept honest. I’ve seen more than one make ridiculous claims: “Turn on your WAF and you are protected from the OWASP Top 10!” It simply is not true. WAFs can detect and stop a lot of common attacks, but there are so many things they cannot detect and/or stop.
WAFs work by searching for dangerous (“blacklist”) patterns and blocking requests that fit those patterns. Blacklist validation can never be perfect, because there are an infinite number of possible inputs yet the blacklist must be finite. Therefore it is just a matter of time before a good hacker finds the right pattern that gets past the WAF.
Moreover, there a number of strategies that hackers can use to bypass WAF blacklists, such as changing the encoding. For good overviews, see WAF through the eyes of hackers and WAF Evasion Techniques.
Last, the suggestion that a WAF can stop all OWASP Top 10 issues (which some vendors will claim) is absurd particularly since some of the attacks on the list do not go through the server at all. For example, DOM-based cross site scripting happens between the attacker and victim without going through the server or WAF. The vulnerability is present due to servers serving up vulnerable JavaScript to the victim. As another example, if the server is sending data via http rather than https, then any person can eavesdrop on it without sending any data to the server at all. WAFs just cannot and do not sprinkle magic fairy dust to make these problems go away.
In the Capital One breach, Amazon is blaming Capital One for not having their WAF stop the SSRF. The reality is that the WAF is the backup protection, and the primary protection should have been at the application level. As I explained in my Understanding Input Validation blog from February 2018 (which by the way talks about how SSRF is often abused on Amazon cloud computing), input validation is the proper way to stop SSRF. That solves the problem exactly where the vulnerability exists — in the code — rather than expecting some add-on security protection to suddenly turn an insecure application into a secure one.
So if it wasn’t a WAF misconfiguration, then whom do we blame?
The joy of recriminations! In fact, I see a lot of failures which are far more significant than the WAF configuration failure. For example:
- Was the application penetration tested? If not, that is a major failure in security process. If it was, then it is a bit surprising to see that this vulnerability was missed — a good penetration tester should have found it.
- Was the application security code reviewed? A good code reviewer with a decent SAST tool could have found the vulnerability. But we could only say that if we know whether Capital One invested in application security — that I do not know.
- Were developers provided application security education? While this is one that is harder to depend upon, it is a recommended best practice of today.
- Maybe Amazon is to shoulder some blame for not making SSRF harder to abuse in their infrastructure? I’ll elaborate on that in the next section.
- Whoever made the business decision to go with AWS, was security part of that decision? I’ll elaborate on that in the next section too.
AWS is like a car without seatbelts!
Recently, Evan Johnson from Cloudflare Inc wrote a blog Preventing the Capital One Breach. That blog hits the nail on the head.
Let’s cut to the chase: The three biggest cloud providers are Amazon AWS, Microsoft Azure, and Google Cloud Platform (GCP). All three have very dangerous instance metadata endpoints, yet Azure and GCP applications seem to never get hit by this dangerous SSRF vulnerability. On the other hand, AWS applications continue to get hit over and over and over again. Does that tell you something?
Microsoft is a company that learned about security the hard way. It took them a long, time before they understood that it is their responsibility to make products that are secure by default and hard for the user to misuse: Putting the responsibility for security in the hands of the user is dangerous. A manifestation of this is in their instance metadata endpoint, which builds in protections to stop SSRF attacks:

I can’t say Google has learned security the hard way, instead I say they just hire a lot of smart people and their business clearly understands the importance of security to their business model. Similar to Microsoft, they built SSRF defences into their instance metadata endpoint:
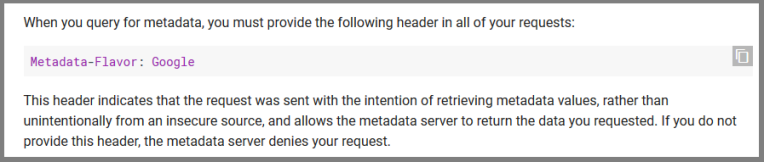
The point is that it is not sufficient for the attacker to be able to just control the url, but the attacker must also be able to set a http header in order to access the metadata endpoint. In most cases, that is outside of the attacker’s control, which makes SSRF a lot less likely to exploit.
If Amazon had similar protections like Microsoft and Google, then it is unlikely that we would be talking about the Capital One security breach right now: it simply would not have happened. So, why won’t Amazon put such protections in their metadata endpoint? Because Amazon believes it is not their responsibility to make their services hard to abuse, instead it’s the customer’s responsibility to get everything perfect themselves.
And that’s where the seatbelt analogy comes in. If these vendors were selling cars, the Microsofts and Googles would be selling the cars with seatbelts — understanding that you might crash, but they have designed the systems to reduce the impact to you. Amazon on the other hand would be the vendor selling the car without seatbelts: if you crash, it’s your own fault. If you die, don’t blame them. They provided a car with a lot of nice features and if you read the manual and drove it exactly as you are expected to, you would have no problems. But let’s be clear, if everything is not perfect, then you accept the consequences and they will let you know it’s your fault and not theirs. See it in their own words:
“The intrusion was caused by a misconfiguration of a web application firewall and not the underlying infrastructure or the location of the infrastructure. AWS is constantly delivering services and functionality to anticipate new threats at scale, offering more security capabilities and layers than customers can find anywhere else including within their own datacenters, and when broadly used, properly configured and monitored, offer unmatched security—and the track record for customers over 13+ years in securely using AWS provides unambiguous proof that these layers work.”
Concluding remarks
Amazon lacks security maturity. They do not understand key concepts that those weathered in the industry have learned over many years of experience. Trying to suggest a firewall is the fix for an application security problem is fundamentally wrong. Relying on people to be experts at configuring firewalls to prevent attacks is a bad strategy: instead they should learn from the Microsofts and Googles about how to build infrastructure that is less fragile and less dependent upon the perfect users. That’s not to say that the other security controls do not have a place, but instead they need to understand that they are backup defences and not primary defences.
Hosting in AWS is like buying a car without seatbelts. If your application gets hit as well, then maybe the stakeholders who pushed for AWS should shoulder the vast majority of the blame. Next time security should be part of the decision making when choosing a cloud provider, which means both Azure and GCP should be preferred over AWS.

One thought on “Thoughts on the Capital One Security Breach”