
Static analysis tools (SAST) are perhaps the most common tool for an AppSec team in the endless effort to move security to the left. They can be integrated into development pipelines in order to offer quick feedback to the developer to catch security bugs, resulting in faster remediation times and improved return on investment for developing secure software.
The SAST market is dominated by a small number of big players that charge high licencing fees for tools that do sophisticated analysis. One of the main features of such tools is the data flow analysis, which traces vulnerabilities from source to sink, potentially going across a number of files. More information about what such tools can do can be found in this Synopsis report. These tools typically can take hours or even days to complete a scan, and may use a large amount of memory. Furthermore, some of the tools have a large number of false positives, and potentially their own eccentricities. For organisations with deep pockets, the benefits outweigh the costs.
There are lower cost, more efficient SAST tools, but they typically do lack the sophistication in terms of quality of security bug findings. Perhaps the most popular low-cost alternative is SonarQube, which is quite popular amont developers. SonarQube does very quick scans, but lacks the data flow analysis capability that the more expensive tools have. As a consequence, security findings are represented in one place (not source-to-sink analysis).
In this blog, we’re going to talk about grep-based code scanning, which is an old fashioned way of SAST scanning — but we argue that good grep based scanning can do reasonably well compared to expensive SAST tools in terms of quality of bugs found. While grep based-scanning in the form we present it cannot do data flow analysis, we claim that the major shortcomings in what we miss are not extensive. We also show examples of things we found that our commercial tool at the time missed. While it is certainly capable that the commercial tools can build up their rule sets to catch everything we catch, it falls upon them to add those rules.
I have experience we three leading SAST tools, but considerable experience with only one of them. I’m not going to call out any names of tools, but I do generally see room for improvement in them.
In order to make this blog the most beneficial to the readers, we will provide a starting pack of grep-based rule sets that we have used. The tools we have developed are not in a state that they can be open sourced, and we do not have the time to fix them up. However, the rules we provide open the door for somebody with that time availability to do so. It takes very little effort to build a PoC in this way.
This is joint work with Jack Healy.
Tool philosophy
False positives seem part of the game in the SAST market. While I have heard of one tool trying to put considerable focus into removing false positives, I have not experienced such features in the tools that I have worked with — at least not “out of the box.” As a consequence, many tools seem to require manual inspection of the findings to remove the junk and focus on the issues that seem real. In our grep-based scanner, we play by the same rules: we assume that the results are going to be inspected manually, and the person running the tool has a basic understanding of security vulnerabilities and how to identify them in code. Thus, grep-based code scanning assumes a certain level of security competence and language expertise by the person running the code scan.
We take the philosophy that is okay to have a large number of false positives if we are looking at something that is very serious and too often a problem — for example, SQL injection. We take the philosophy that it is not okay to have a lot of false positives if the issues is not that serious (by CVSS rating). Generally, we are not trying to find everything, but instead trying to maximise the value we get out of our code scanning under a manual inspection time constraint. It’s worth spending extra time for catching the big fish, not for the small ones.
Depending upon how the tool is used, we may under some conditions want to report only things that are high confidence, and ignore everything else. A common example is in a CICD environment, where you want to break a build only if you are quite confident that something is wrong. So in our case, we have an option to only report very high confidence results. We also allow developers to flag false positives similar to how SonarQube does it, thus making it developer friendly.
What do we lose by not having data flow analysis?
While the expensive tools have the advantage of data flow analysis, our belief is that we can get a lot of what they get without it. The biggest exception is cross-site scripting, which our grep-based scanner does not find. We consider alternative tooling such as DAST to be an option for finding this serious issue.
Another example of an important issue that we are unlikely to find is logging of sensitive information. Typically that does require some type of data flow analysis — you’re almost never going to find code that directly does something direct like Log(password).
But something like SQL injection, we have found a number of times. The reason being — we report every SQL query we find. Yes, it’s noisy, but it takes a code reviewer at most 10 seconds of manual inspection time to see if there is a string concatenation in the query, and if that’s the case, it may be vulnerable. If not, the reviewer can quickly dismiss it as a false positive. Obviously more sophisticated code scanning can make this less noisy (example: regular expression code scanning), but this is our starting point.
Certainly tools with data flow analysis are more efficient for something important like SQL injection. However the benefit from that efficiency is often lost when weighed against how much manual time is lost on false positives for issues that are not that important and/or low confidence. Furthermore, some tools do not do so well in terms of rating the seriousness of a vulnerability: they can be over-zealous in calling too many issues critical or high risk (though this may be configurable). Because of this, the overall usage of our tool — at least for us — seems to require similar manual effort as some of the popular commercial tools despite the simplicity of the design.
Examples of things we found that our main commercial tool missed
Because of the simplicity of our design and because we assume that a competent reviewer is going to look a the code, we were able to put in rules that help the reviewer find things that big commercial tools tend to miss.
One very fruitful area in finding security bugs is bad crypto. As mentioned in Top 10 Developer Crypto Mistakes, bad crypto is more prevalent than good crypto. Part of the reason for this is bad crypto APIs. Another part of the reason is that the tools don’t help developers catch mistakes. Vendors of these tools could find a lot more problems if they were to listen to cryptographers. Our tool flags any use of “crypt” and any other key words that are indicative of bad cryptography, such as rc4, arcfour, md5, sha1, TripleDES, etc…. We go into more details about crypto bugs in the rules sets.
Another issue that we find surprisingly often that our main commercial tool missed was http://. Of course it should always be https://. Similarly one can look for ftp:// and other insecure protocols.
There are also a number of dangerous functions that we flag, and often these open up discussions about coding practices. For example, the Angluar trustAsHtml or React dangerouslySetInnerHTML. In our case, we had to educate the developers on the right approach to handle untrusted data, because they thought it was safe to sanitise data prior to putting in the database and then use trustAsHtml upon display. We did not agree with this coding style and worked to change it.
One thing that we like to always look at is MVC controller functionality because sometimes that’s where input validation should be applied (in other times you might do it in the model). We often find a lack of input validation, which does not necessarily imply a vulnerability but does show the need for improved defensive programming. Even more interesting, one time when we looked at a controller, we found that it was obviously not doing access control checking that it should be doing, and this was one of the most major findings that we caught. Normally access control problems are not something you would find with a SAST tool, but our differing approach to how to use the tool made it work for us.
Sample rules: starter pack
Rules can go on forever, so here I want to just focus on some of the more fruitful ones to get you started. Generally we do a case insensitive grep to find the key word, and then we grep out (“grep -v”) things that got in by chance but are not actually the key word we are looking for. We call these “exceptions” to our rules. For example “3des” is indicative of the insecure triple DES encryption algorithm, but we wouldn’t want to pull in a variable like “S3Destination”, which our developers might use for Amazon S3 storage (nothing to do with triple DES). We learn the exceptions over time.
A very common grep rule that we need to make exceptions for is “http:”. While we are looking for insecure transport layer communications, the problem is that “http:” is also used in XML namespaces that have nothing to do with transport layer security. This means we have to grep out things like “xmlns”. Also, writing logic to ignore commented code helps a lot — otherwise you will pull in many false positives like license example (http://www.apache.org/licenses) or stackoverflow links, which often occur in comments.
It may look like we omitted some obvious rules in some cases, but sometimes there are subtle reasons. For example, even though we do a lot of crypto rules, we don’t do an “ECB” (insecure electronic code book mode of operation) search simply because it is too noisy. Those characters “E”, “C”, and “B” all look like hexadecimal numbers, and we often got false positives from hexadecimal values in code. It was deemed not fruitful enough to keep such a rule (as explained in our design philosophy above).
We also try to group our rule by language to reduce false positives. However some rules apply to all languages. In our case we are primarily working on web software so we don’t specify languages like C/C++, etc…
Below is the starter pack of rules. Some rules are clearly more noisy than others — people can pick and choose the ones they want to focus on.
| Grep string | Look for | Languages |
|---|---|---|
| password, passwd, credential, passphrase | Hardcoded passwords, insecure password storage, insecure password transmission, password policy, etc…. | all |
| sql, query( | sql injection (string concatenation) | all |
| strcat, strcpy, strncat, strncpy, sprintf, gets | dangerous C functions used in iOS | iOS |
| setAllowsAnyHTTPSCertificate, validatesSecureCertificate, allowInvalidCertificates, kCFStreamSSLValidatesCertificateChain | disables TLS cert checking | iOS |
| crypt | hardcoded keys, fixed IVs, confusing encryption with message integrity, hardcoded salts, crypto soup, insecure mode of operation for symmetric cipher, misuse of a hash function, confusing a password with a crypto key, insecure randomness, key size too small. See Top 10 Developer Crypto Mistakes | all |
| CCCrypt | IV is not optional (Apple API documentation is wrong) if security is required | iOS |
| md5, sha1, sha-1 | insecure, deprecate hash function | all |
| 3des, des3, TripleDES | insecure deprecate encryption function | all |
| debuggable | do not ship debugabble code | android |
| WRITE_EXTERNAL_STORAGE, sdcard, getExternalStorageDirectory, isExternalStorageWritable | check that sensitive data is not being written to insecure storage | android |
| MODE_WORLD_READABLE, MODE_WORLD_WRITEABLE | should never make files world readable or writeable | android |
| SSLSocketFactory | dangerous functionality — insecure API, easy to make mistakes | java |
| SecretKeySpec | verify that crypto keys are not hardcoded | java |
| PBEParameterSpec | verify salt is not hardcoded and iterations is at least 10,000 | c# |
| PasswordDeriveBytes | insecure password based key derivation function (PBKDF1) | c# |
| rc4, arcfour | deprecated, insecure stream cipher | all |
| exec( | remote code execution if user input is sent in | java |
| eval( | remote code execution if user input is sent in | javascript |
| http: | insecure transport layer security, need https: | all |
| ftp: | insecure file transfer, need ftps: | all |
| ALLOW_ALL_HOSTNAME_VERIFIER, AllowAllHostnameVerifier | certificate checking disabled | java |
| printStackTrace | should not output stack traces (information disclosure) | java, jsp |
| readObject( | potential deserialization vulnerability if input is untrusted | java |
| dangerouslySetInnerHTML | dangerous React functionality (XSS) | javascript |
| trustAsHtml | dangerous Angular functionality
(XSS) |
javascript |
| Math.random( | not cryptographically secure | javascript |
| java.util.Random | not cryptographically secure | java |
| SAXParserFactory, DOM4J, XMLInputFactory, TransformerFactory, javax.xml.validation.Validator, SchemaFactory, SAXTransformerFactory, XMLReader SAXBuilder, SAXReader, javax.xml.bind.Unmarshaller, XPathExpression DOMSource, StAXSource | vulnerable to XXE by default | java |
| controller | MVC controller functionality: check for input validation | c#, java |
| HttpServletRequest | check for input validation | java |
| request.getParameter | check for input validation | jsp |
| exec | dynamic sql: potential for sql injection | sql |
| getAcceptedIssuers | If null is returned, then TLS host name verification is disabled | android |
| isTrusted | If returns true, then TLS validation is disabled | java |
| trustmanager | could be used to skip cert checking | java |
| ServerCertificateValidationCallback | If returns true, then TLS validation is disabled | c# |
| checkCertificateName | If set to false, then hostname verification is disabled | c# |
| checkCertificateRevocationList | If set to false, then CRLS not checked | c# |
| NODE_TLS_REJECT_UNAUTHORIZED | certificate checking is disabled | javascript |
| rejectUnauthorized, insecure, strictSSL, clientPemCrtSignedBySelfSignedRootCaBuffer | cert checking may be disabled | javascript |
| NSExceptionDomains, NSAllowsArbitraryLoads, NSExceptionAllowsInsecureHTTPLoads | allows http instead of https traffic | iOS |
| kSSLProtocol3, kSSLProtocol2, kSSLProtocolAll, NSExceptionMinimumTLSVersion | allows insecure SSL communications | iOS |
| public-read | publicly readable Amazon S3 bucket — make sure no confidential data stored | all |
| AWS_KEY | look for hardcoded AWS keys | all |
| urllib3.disable_warnings | certificate checking may be disabled | python |
| ssl_version | can be used to allow insecure SSL comms | python |
| cookie | make sure cookies set secure and httpOnly attributes | all |
| kSecAttrAccessibleAlways | insecure keychain access | iOS |
 Upon hitting enter, you might see that the script executes (reflected XSS):
Upon hitting enter, you might see that the script executes (reflected XSS): However, you also might not see this. For example, if you try running it in a corporate environment, then the company proxy might have stopped it (one of the problems I ran into). If you use Chrome, you might have found that Chrome blocked it (one of the problems that the audience ran into when trying it — see screenshot below). There are workarounds for both cases, but it blunts the point of the severity of the issue when it only works in special cases.
However, you also might not see this. For example, if you try running it in a corporate environment, then the company proxy might have stopped it (one of the problems I ran into). If you use Chrome, you might have found that Chrome blocked it (one of the problems that the audience ran into when trying it — see screenshot below). There are workarounds for both cases, but it blunts the point of the severity of the issue when it only works in special cases. Now let’s try the exact same thing in
Now let’s try the exact same thing in  Upon hitting enter, I’m quite sure you will see this (DOM-based XSS):
Upon hitting enter, I’m quite sure you will see this (DOM-based XSS): In my case, neither the corporate proxy nor Chrome blocked it. There is a good reason for that.
In my case, neither the corporate proxy nor Chrome blocked it. There is a good reason for that. We see that the script entered in the search bar was reflected back as part of the html.
We see that the script entered in the search bar was reflected back as part of the html. It was not reflected back.
It was not reflected back.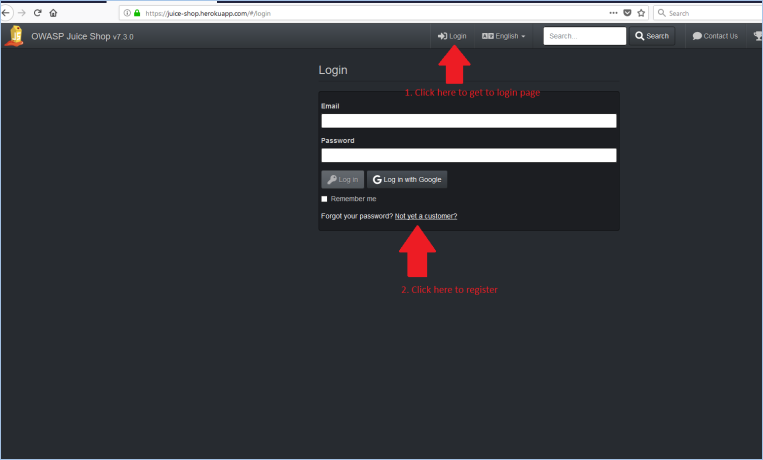 From there you create the account of your victim user:
From there you create the account of your victim user: Next, the victim logs in:
Next, the victim logs in: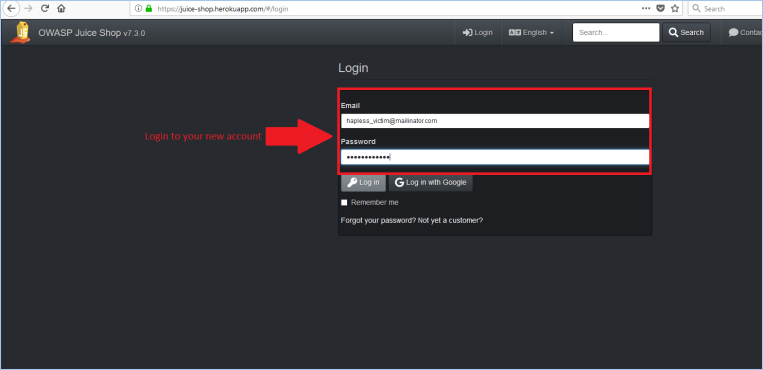 All is fine and dandy, until somebody tells the victim of a website that offers free juice to OWASP Juice Shop customers. What could be better! The victim rushes to the site (for our temporary deployment, link is:
All is fine and dandy, until somebody tells the victim of a website that offers free juice to OWASP Juice Shop customers. What could be better! The victim rushes to the site (for our temporary deployment, link is:  Upon clicking the link, the DOM-based XSS is triggered. A nontechnical user would likely not understand that a script has executed from the malicious site. In fact, in this case, the script has taken the victim’s cookie and sent it to the malicious website. The malicious website has a “/recorddata” endpoint that records the cookie in a temporary file (a more serious implementation would use a database).
Upon clicking the link, the DOM-based XSS is triggered. A nontechnical user would likely not understand that a script has executed from the malicious site. In fact, in this case, the script has taken the victim’s cookie and sent it to the malicious website. The malicious website has a “/recorddata” endpoint that records the cookie in a temporary file (a more serious implementation would use a database). Our malicious server also has a “/dumpdata” endpoint for displaying all the captured cookies (
Our malicious server also has a “/dumpdata” endpoint for displaying all the captured cookies (
 And now head over to
And now head over to  Amazing! The username and password are in the cookie. But that’s not the real password, so what is it? Let’s Google it:
Amazing! The username and password are in the cookie. But that’s not the real password, so what is it? Let’s Google it: And clicking the first link, we find out that it was the MD5 hash of the password. The real password is revealed in the link:
And clicking the first link, we find out that it was the MD5 hash of the password. The real password is revealed in the link:









{kind=link}